
Huffman Coding
Bagaimana algoritma kompresi sederhana seperti Huffman Coding bisa berdampak besar dalam pengelolaan data skala besar? Dalam tulisan ini, kita bahas bagaimana Huffman Coding—yang sering kali dianggap teori lama—masih sangat relevan untuk ekosistem Big Data modern. Dari efisiensi penyimpanan hingga percepatan proses distribusi data antar-node, Huffman menawarkan solusi yang ringan tapi strategis.
Abdiel
5/9/20252 min read
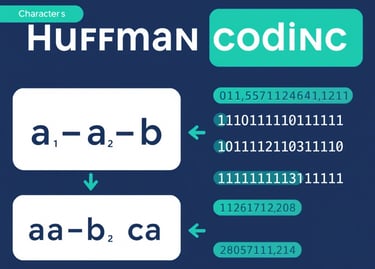
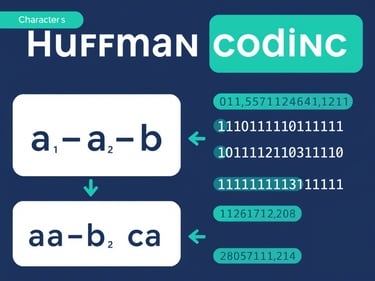
Di era Big Data, organisasi menghadapi tantangan dalam mengelola volume data yang terus bertambah secara eksponensial. Setiap bit data yang disimpan dan diproses memiliki implikasi langsung terhadap performa sistem, biaya operasional, dan waktu respons analitik.
Salah satu solusi klasik namun sangat relevan untuk tantangan ini adalah penggunaan algoritma kompresi lossless, seperti Huffman Coding.
Huffman Coding adalah algoritma kompresi data yang ditemukan oleh David A. Huffman pada tahun 1952. Teknik ini mengompresi data tanpa kehilangan informasi (lossless) dengan cara memberikan kode lebih pendek pada karakter yang sering muncul dan kode lebih panjang pada karakter yang jarang muncul. Hasilnya adalah representasi biner data yang lebih efisien.
Relevansi Huffman Coding dalam Ekosistem Big Data
Di dalam ekosistem Big Data modern—baik yang berbasis Hadoop, Spark, maupun lakehouse architecture seperti Delta Lake dan Apache Iceberg—efisiensi dalam penyimpanan dan transfer data sangat krusial.
Huffman Coding berperan sebagai salah satu metode yang dapat diterapkan pada tahap preprocessing atau sebagai bagian dari format penyimpanan yang mendukung kompresi (misalnya ORC dan Parquet).
Manfaat Praktis:
Optimalisasi Ingest Data:
Kompresi data sebelum ingestion dapat mempercepat proses pemuatan dan meminimalkan bottleneck.
Efisiensi Penyimpanan:
Mengurangi ukuran file secara signifikan, sehingga menekan biaya penyimpanan di cloud storage seperti Amazon S3 atau Google Cloud Storage.
Performa Query yang Lebih Baik:
Engine seperti Apache Presto, Amazon Athena, dan Google BigQuery dapat membaca data terkompresi lebih cepat, terutama jika dikombinasikan dengan format kolumnar.
Transfer Antar-Node Lebih Cepat:
Dalam distributed computing, pengurangan ukuran data berdampak langsung pada kecepatan distribusi dan sinkronisasi antar-node.
Studi Kasus Sederhana
Misalnya, sebuah string teks seperti "this is an example for huffman coding" secara normal membutuhkan sekitar 336 bit (42 karakter x 8 bit). Dengan Huffman Coding, ukuran ini bisa dikompresi menjadi hanya 197 bit—penghematan lebih dari 40%.
Dalam skala besar, penghematan ini menjadi sangat signifikan. Bayangkan mengurangi 40% dari ukuran dataset berukuran terabyte—dampaknya terhadap biaya dan performa sangat besar.
Kesimpulan
Huffman Coding adalah teknik fundamental yang tetap relevan di era modern. Meski sederhana, ia memberikan nilai strategis dalam pengelolaan data skala besar. Dengan memahami dan mengimplementasikan teknik kompresi seperti Huffman, praktisi Big Data dapat merancang pipeline data yang lebih hemat biaya, lebih cepat, dan lebih andal.
Efisiensi kecil pada level bit dapat menghasilkan dampak besar pada level sistem. Huffman Coding adalah buktinya.